Definition 1: Given a square matrix A, an eigenvalue is a scalar λ such that det (A – λI) = 0, where A is a k × k matrix and I is the k × k identity matrix. The eigenvalue with the largest absolute value is called the dominant eigenvalue.
Observation: det (A – λI) = 0 expands into a kth degree polynomial equation in the unknown λ called the characteristic equation. The polynomial itself is called the characteristic polynomial. The solutions to the characteristic equation are the eigenvalues. Since, based on the fundamental theorem of algebra, any kth degree polynomial p(x) has n roots (i.e. solutions to the equation p(x) = 0), we conclude that any k × k matrix has k eigenvalues.
Example 1: Find the eigenvalues for matrix A
![]()
![]()
Thus
![]()
This is the characteristic equation. Solving for λ, we have the eigenvalues λ = 3 and λ = 14.
Observation: Let A = ![\left[\begin{array}{cc} a & b \\ d & e \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7D+a+%26+b+%5C%5C+d+%26+e+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "\left[\begin{array}{cc} a & b \\ d & e \end{array}\right]")
![]()
![]()
![]()
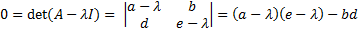{kind=link}
![]()
Now let λ1 and λ2 be the eigenvalues. Then (λ – λ1)(λ – λ2)=0, and so λ2 – (λ1 + λ2)λ+ λ1 λ2, and so λ1 + λ2 = trace A and λ1 λ2 = det A.
This is consistent with the eigenvalues from Example 1.
In fact, these properties are true in general, not just for 2 × 2 matrices.
Property 1:
- The product of all the eigenvalues of A = det A
- The sum of all the eigenvalues of A = trace A
- A square matrix is invertible if and only if it none of its eigenvalues is zero.
- The eigenvalues of an upper triangular matrix (including a diagonal matrix) are the entries on the main diagonal
Proof:
a) By definition, each eigenvalue is a root of the characteristic equation det(A – λI) = 0. By Definition 1 of Determinants and Simultaneous Linear Equations, det(A – λI) can be expressed as a kth degree polynomial in the form 

![]()
b) Note that if you expand the terms of det(A – λI) =
![]()
If you expand the terms of det(A – λI) =
![]()
Thus, trace A = a11 + a22 + ⋯ + akk = λ1 + λ2 + ⋯ + λk.
c) Results from (a) and Property 4 of Determinants and Simultaneous Linear Equations.
d) If A is an upper triangular matrix, then so is A – λI. The result now follows from Definition 1 of Determinants and Simultaneous Linear Equations.
Example 2: Find the eigenvalues for the matrix A where
![]()
We evaluate![]()
![]()
![]()
![]()
Thus, the characteristic equation is
![]()
Factoring the polynomial yields
![]()
and so the eigenvalues are 0, 3 and -1.
Definition 2: If λ is an eigenvalue of the k × k matrix A, then a non-zero k × 1 matrix X is an eigenvector which corresponds to λ provided (A – λI)X = 0, where 0 is the k × k null matrix (i.e. 0’s in all positions).
Property 2: Every eigenvalue of a square matrix has an infinite number of corresponding eigenvectors.
Proof: Let λ be an eigenvalue of a k × k matrix A. Thus by Definition 1, det (A – λI) = 0, and so by Property 3 and 4 of Rank of a Matrix, (A – λI)X = 0 has an infinite number of solutions. Each such solution is an eigenvector.
Property 3: X is an eigenvector corresponding to eigenvalue λ if and only if AX = λX. If X is an eigenvector corresponding to λ, then every non-zero scalar multiple of X is also an eigenvector corresponding to λ.
Proof: Let λ be an eigenvalue of a k × k matrix A and let X be an eigenvector corresponding to λ. Then as we saw in the proof of Property 2, (A – λI)X = 0, an assertion which is equivalent to AX = λX. The converse is obvious.
Now let c be a non-zero scalar. Then A(cX) = c(AX) = c(λX) = λ(cX), and so cX is also an eigenvector.
Property 4: If λ is an eigenvalue of an invertible matrix A then λ-1 is an eigenvalue of A-1. Thus, the smallest eigenvalue of A = the reciprocal of the dominant eigenvalue of A-1
Proof: If λ is an eigenvalue, then there is a vector X ≠ 0, such that AX = λX. Thus A-1AX = A-1λX, and so X = A-1 λX = λA-1X. Dividing both sides of the equation by λ yields the result λ-1X = A-1X.
Property 5: If λ is an eigenvalue of the k × k matrix A and X is a corresponding eigenvector, then 1 + λ is an eigenvalue of I + A with corresponding eigenvector X.
Proof: Since (A – λI) X = 0, we have ((I + A) – (1 + λ)I) X = X + AX – X – λX = AX – λX = (A – λI) X = 0.
Example 3: Find the eigenvectors for A from Example 1.
![]()
This equivalent to
x(13–λ) + 5y = 0
2x + (4–λ)y = 0
For λ = 3
10x + 5y = 0
2x + y = 0
Thus, y = -2x, which means ![\left[\begin{array}{c} x \\ y \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "\left[\begin{array}{c} x \\ y \end{array}\right]")
![\left[\begin{array}{c} -1 \\ 2 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+-1+%5C%5C+2+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "\left[\begin{array}{c} -1 \\ 2 \end{array}\right]")
For λ = 14
–x + 5y = 0
2x – 10y = 0
Thus, x = 5y, which means ![\left[\begin{array}{c} 5 \\ 1 \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+5+%5C%5C+1+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "\left[\begin{array}{c} 5 \\ 1 \end{array}\right]")
We now find the eigenvectors with unit length.
For eigenvalue λ = 3, an eigenvector is ^2+2^2}")

![\left[\begin{array}{c} -1/\sqrt{5} \\ 2/\sqrt{5} \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+-1%2F%5Csqrt%7B5%7D+%5C%5C+2%2F%5Csqrt%7B5%7D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "\left[\begin{array}{c} -1/\sqrt{5} \\ 2/\sqrt{5} \end{array}\right]")
For λ = 14, an eigenvector is 

![\left[\begin{array}{c} 5/\sqrt{26} \\ 1/\sqrt{26} \end{array}\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cbegin%7Barray%7D%7Bc%7D+5%2F%5Csqrt%7B26%7D+%5C%5C+1%2F%5Csqrt%7B26%7D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=000000&s=0 "\left[\begin{array}{c} 5/\sqrt{26} \\ 1/\sqrt{26} \end{array}\right]")
Property 6: If X is an eigenvector then the Rayleigh Quotient = (XTAX) / (XTX) is a corresponding eigenvalue
Proof: (XTAX) / (XTX) = (XTλX) / (XTX) = λ (XTX) / (XTX) = λ where λ is the eigenvalue that corresponds to X
Example 4: Find the eigenvalues for the two unit eigenvectors from Example 3.
If AX = λX, then (A – λI) X = 0, and so λ is an eigenvalue corresponding to the eigenvector X. Since
![]()
![]()
it follows that λ = 3 and λ = 14 are the two corresponding eigenvalues.
Another approach is to use Rayleigh Quotient = (XTAX) / (XTX) per Property 6. For example
![]()
![]()
Thus, λ = 15/5 = 3.
Property 7: If all the eigenvalues of a square matrix A are distinct then any set of eigenvectors corresponding to these eigenvalues are independent.
Proof: We prove the result by induction on k. Suppose λ1, …, λk are the eigenvalues of A and suppose they are all distinct. Suppose that X1, …, Xk are the corresponding eigenvectors and b1X1 + … + bkXk = 0. Thus,
0 = A0 = b1AX1 + … + bkAXk = b1λ1X1 + … + bkλkXk
But also
0 = b1λ1X1 + … + bkλ1Xk
Subtracting these linear combinations from each other, we get:
0 = b2(λ2 – λ1) X2 + … + bk(λk – λ1) Xk
Since this is a linear combination of k – 1 of the eigenvectors, by the induction hypothesis, b2(λ2 – λ1) = 0, …, bk(λk – λ1) = 0. But since all the λi are distinct, the expressions in parentheses are non-zero, and so b2 = … = bk = 0. Thus 0 = b1X1 + … + bkXk = b1X1 + 0 + … + 0 = b1X1. since X1 is an eigenvector X1 ≠ 0, and so b1 = 0. This proves that all the bi = 0, and so X1, …, Xk are independent.
Property 8: If the eigenvalues of a square k × k matrix A are distinct, then any set of eigenvectors corresponding to these eigenvalues are a basis for the set of all k × 1 column vectors (and so any set of k × 1 vector can be expressed uniquely as a linear combination of these eigenvectors).
Proof: The result follows from Corollary 4 of Linear Independent Vectors and Property 7.
Definition 3: A square matrix A is diagonalizable if there exists an invertible matrix P and a diagonal matrix D such that A = PDP-1.
Property 9: For any square matrix A and invertible matrix P, the matrices A and PDP-1 have the same eigenvalues.
Proof: This follows since A and B have the same characteristic equation:
![]()
![]()
Property 10: An n × n matrix is diagonalizable if and only if it has n linearly independent eigenvectors.
Proof: First we show that if A is diagonalizable then A has n linearly independent eigenvectors.
Suppose A = PDP-1 where D = [dij] is a diagonal matrix and P is invertible. Thus AP = PD. Let Pj be the jth column of P. Thus the jth column of AP is APj and the jth column of PD is djj Pj. Since AP = PD, it follows that APj = djj Pj, which means that djj is an eigenvalue of A with corresponding eigenvector Pj.
Since P is invertible, by Property 9, rank(P) = n, and so the columns of P are linearly independent. But the columns of P are the eigenvectors, thus showing that the eigenvectors are independent.
Next, we show that if A has n linearly independent eigenvectors then A is diagonalizable.
Let P1, …, Pn be the n linearly independent eigenvectors of A and let P be the n × n matrix whose columns are the Pj. Let λ1, …, λn be the eigenvalues of A and let D = [dij] be the diagonal matrix whose main diagonal contains these eigenvalues. Since APj = λj Pj, it follows that the jth column of AP = the jth column of PD and so AP = PD, from which it follows that A = PDP-1.
Observation: The proof of Property 10, shows that for any square matric A, if for some diagonal matrix D and invertible matrix P, then the main diagonal of D consists of the eigenvalues of A and the columns of P are corresponding eigenvectors.
Property 11: If A has n distinct real eigenvalues then A is diagonalizable.
Proof: The result follows from Property 7 and 10.
Observation: The converse of Property 11 is not true. E.g. the n × n identity matrix is trivially diagonalizable but it does not have n distinct eigenvalues.
Observation: Every square k × k matrix has at most k (real) eigenvalues. If A is symmetric then it has k (real) eigenvalues, although these won’t necessarily be distinct (see Symmetric Matrices). It turns out that the eigenvalues for covariance and correlation matrices are always non-negative (see Positive Definite Matrices).
If A is not symmetric, then some of the eigenvalues may be complex numbers. These complex eigenvalues always occur in pairs, and so for example a 3 × 3 matrix will have either 1 or 3 real eigenvalues, never 2.
Real Statistics Capabilities
Click here for a description of the Real Statistics functions that calculate the eigenvalues and eigenvectors of square matrices.
Click here for how to obtain distinct eigenvectors for repeated eigenvalues, i.e. eigenvalues with multiplicity > 1.
Click here for how to obtain eigenvectors that correspond to complex eigenvalues.
References
Wikipedia (2021) Eigenvalues and eigenvectors
https://en.wikipedia.org/wiki/Eigenvalues_and_eigenvectors
Hello. Negative Eigenvalues. I created a correlation matrix (symmetric, square, 10×10) using 1 on the diagonal and random numbers for the off diagonal values. I made the matrix symmetric (x(2,1) = x(1,2) etc.) I used the eigValReal() and obtained several negative eigenvalues. I compared to MathCAD and obtained the exact same results. However, when I used the Jacobi program version for eigenvalues, I get the exact same values as yours and MathcCAD but all positive (no negative values).
I got the Jacobi method program from the usual (Numerical Methods in Fortran, and some linear algebra (reinsch).
My question is I obtained several negative eigenvalues using your program/MathCAD, but all positive values for the same square symmetric matrix using the Jacobi method. And ALL values were exactly identical (except for the sign for the few negative eigenvalues).
How can I tell which is the right set of eigenvalues and not due to something in the way each program calculates the eigenvalues? It seems I have one set of eigenvalues (all methods gave the exact same numbers) but yours/MathCAD had a few with negative signs, and the Jacobi method had all positive signs.
Thanks
As an add on, I think one definition for Pos-Definite is that all eigenvalues are positive. So, given the same matrix, yours/MathCAD gave me some negative eigenvalues meaning that it does not meet one criteria for Pos-Definite, and the Jacobi calculations gave all positive meaning that it meets that part of being a Pos-Definite matrix.
Thanks!
Dan,
If you email me the matrix and your results, I will try to figure out what is happening.
Note that if the value is close to zero, such as -2.56E-15, then you could get a negative value even if the value can’t be negative since this value is really treated as zero.
Charles
Hello
As you will see from the data I sent, close to ‘0’ is not the issue.
Thanks
Dan,
Thanks for emailing the matrix. I see that the matrix is real and symmetric and some of the eigenvalues are negative. I also see that the eigenvalues produced by MathCAD are identical to those produced by Real Statistics, at least to 13 or 14 decimal places, including the sign. I can only conclude that the matrix is not positive definite. If you believe that it is the correlation matrix for some data, then I would need to see the original data.
Charles
Thanks, I have another way to check. There is a method to create a matrix with negative eigenvalues; hence, I will know that the values are negative, and then try. The other possibility is that the Jacobi method might be limited to generating only positive eigenvalues, i. e. some squaring and/or absolute function imposed.
I will compare with the usual powerhouse programs such as Mathematica, R, etc. Minitab 13 can do the analysis but I think the rounding errors are too much and and the values are not the same at all. Might be due to rounding errors or algorithm used. (Makes me question Minitab which is a powerhouse program used for so many statistical applications!)
The data were generated using Math.RND(), and just random data — not ‘real’ data (with ‘1’ imposed on the diagonal).
When I looked up negative eigenvalues, there was a design program that had a built in ‘warning’ for negative eigenvalues under the assumption that there was a real problem with a ‘material stress’ result.
(“Abaqus”, and one user responded with “Sometimes, negative eigenvalues are reported in an eigenvalue buckling analysis. In most cases such negative eigenvalues indicate that the structure would buckle if the load were applied in the opposite direction. A classical example is a plate under shear loading; the plate will buckle at the same value for positive and negative applied shear load…..”)
It is interesting that this has a real-world significance.
Thanks for looking into it, and I will continue to try to find an answer. If I find out something, I will post. If you run across something, or an alternate ‘true math’ reasoning as to resolve, please email me and/or post as I will check from time to time.
Thanks!
Hi Dan,
If you generated values at random, then there is no reason to believe that the matrix is positive definite even if all the values are positive and the diagonal contains 1’s.
Charles
Also, is there a way to demonstrate Pos-Definite or not without using eigenvalues?
Thanks
Dan,
The easiest way I know is to see whether all the eigenvalues are positive real numbers. See also
https://www.real-statistics.com/linear-algebra-matrix-topics/positive-definite-matrices/
Charles
I think I found the easy solution without eigenvalues. In a paper I found a statement:
“A matrix is positive definite if it’s symmetric and all its pivots are positive”
Which was shown that if you do the usual elimination to form the upper triangle, then if all diagonal elements are positive, you have a Pos Def matrix. This should relate to the eigenvalues in that the diagonal of an upper or lower triangle will be the eigenvalues of that triangle. The values of the diagonal will not be equivalent to the eigenvalues of the original matrix (unless you do something similar to a Householder transformation, I think, where the eigenvalues are preserved).
I applied this to the various matrices that were not Pos Def because of negative eigenvalues and found negative diagonal elements post creating the upper triangle.
I think that this resolves this. Am I applying this correctly?
Thanks
Hi Dan,
I believe that I read something similar to this in the past. It seems that you are on the right track.
Charles
So far eVectors has always returned normalized vectors is this always the case?
Yes
Two questions.
1) You said, “The eVECTORS function will only work reliably for symmetric matrices.” So does that mean I should not use eVECTORS to find the eigenvalues and their associated eigenvectors for the matrix A given in Example 2?
2) Using both eVECTORS and eVECT to find the eigenvalues and their associated eigenvectors for the matrix A given in Example 2, I see they give the same eigenvalues (3,-1,0), but the eigenvectors associated with eigenvalues -1 and 0 are different. Why?
Hello Jacob,
1) Yes, that is correct. The eigenvalues should be the same though.
2) Yes. The eVECTORS algorithm only works for symmetric matrices and so the eigenvector values may be incorrect.
Charles
i need to find eigenvalues for a 6 by 6 matrix, how is it done
You can use the approach used in Example 2 and then find the roots of the resulting characteristic equation (which is of degree 6) using Newton’s method or Bairstow’s method (both of which are described on the Real Statistics website).
This approach though can be rather tedious. Instead you can use the approaches described on the following webpages:
https://real-statistics.com/linear-algebra-matrix-topics/qr-factorization/
https://real-statistics.com/linear-algebra-matrix-topics/eigenvectors-for-non-symmetric-matrices/
The easiest approach is to use the eVALUES function supplied by Real Statistics.
Charles
i want to know about how to equate the eigen values of 3*3 matrix…plz help me
Suhani,
I have now revised the webpage to show how to find the eigenvalues of a 3 x 3 matrix. See Example 2.
Charles
I want to have the Eigen values from correlation matrix in Excel using eVECTORS formula but even following everything correct I am getting single value only
pp ph ngl yld
pp 1 0.239605216 0.285269944 0.385935933
ph 0.239605216 1 0.088659701 0.332323029
ngl 0.285269944 0.088659701 1 0.278784234
yld 0.385935933 0.332323029 0.278784234 1
This is my correlation table but even after using eVECTORS I am getting only one value 1.825 ,, but I should get a matrix of Eigen vectors along with Eigen value
Mukesh,
eVECTORS is what Excel calls an array function and so you can’t simply press the Enter key to get the answer. See the following webpage for how you need to handle array functions (it’s not hard):
Array Formulas and Functions
Charles
Thank you foe reply but I could not get it.. Please explain stepwise, using my example
Thank you I got it
I want to calculate the eigenvectors of a 3×3 matrix. I have the matrix values in one excel row (hence a range of width 9). I do not want to copy the values to a separate array. I would rather like to have a reference function, which returns a reference to a 3×3 array from a row. The reference would then be input to eVECTORS.
Any ideas?
Oliver, what you need is an Excel function XYZ(R1, 3, 3) that takes a row range R1 and converts it into a 3 x 3 range. Then you could use =eVECTORS(XYZ(R1,3,3)). RESHAPE is a similar function, but it reshapes R1 to the size and shape of the highlighted range.
I can’t think of a way of doing this without creating a new user defined function. I will look into doing this in the next release of the software, but I can’t promise it.
Charles
Charles,
I want to use the function eVECTORS, but I met some problems. A window hopped up and I copied it down:
Compile error in hidden module: Matrix.
This error commonly occurs when code is incompatible with the version, platform, or architecture of this application.
My excel is included in the package “Microsoft Office 365 ProPlus”. I wonder how I can get it work.
I also try it in my school’s computer, the excel of which is included in “Microsoft Office Professional Plus 2013”. And it seems that the problems all exists. The same window hopped up.
—
Best
White
White,
The usual reason is that you need to make sure that Excel’s Solver is operational before you install the Real Statistics Resource Pack. This is described in the installation instructions (on the same webpage from which you downloaded the Real Statistics software).
To see whether Solver is operational, press Alt-TI and see whether Solver appears on the list with a check mark next to it. If there is no check mark, you need to add it.
Charles
Hi Charles
I installed the realstat but Eigenvalue and Eigenvector is a single value for nxn matrix. Moreover, these values are same. Please provide me a guideline
Saket
Hi Saket,
The Real Statistics functions eVECTORS and eVECT that return the eigenvalues/vectors of an n x n matrix both return a range of values and not just one value. If you send me an Excel file with your n x n matrix I will try to figure out what is happening. You can get my email address at Contact Us.
Charles
Thanks
I just send you
Saket,
I just responded to your email.
Charles
Thanks Charles
I got it. Thanks for the guidance. It is a wonderful add in. Great job.
Saket
Hi, Charles.
I have a similar problem, just 1 eVal, 1 evect
Can you send me the guideline too?
Thank you.
Lily,
eVALUES and eVECTORS are array functions and so you need to look at the following webpage to understand how you get the other eigenvalues and eigenvectors.
https://real-statistics.com/excel-environment/array-formulas-functions/
Charles
Hi Charles,
Big users of your extremely helpful add-in. It is the best-kept secret for industrial statisticians, and I can’t believe I haven’t been using this sooner.
I just wanted to confirm that the output of the n+3 by n area from the eVECTORS function is in fact using a QR decomposition process, comparable to the Francis/Kublanovskaya algorithm?
Thank you again for all of your very important work.
Hi Victor,
The eVECTORS function does use the QR decomposition.
The eVECT function uses the QR decomposition as well as the Schur decomposition.
Charles
Thank you, Charles. Much obliged for your quick response.
You’re welcome. Good luck with both of those releases. I hope they go smoothly for you.
Thanks for the quick turnaround on my question, Charles. I’ve been toying with the summation of a signed square of the inner product (an adaption of what appears on page 12 in “Resolving the sign ambiguity in the singular value decomposition” of 2007 by R. Bro, E., acar, and T. Kolda at Sandia National Laboratories, an article I sourced recently via an online search).
So far I’ve simply been trying to replicate in Matlab the eVECTOR sign results for one covariance matrix, because they seem to make sense relative to the ‘geometry’ of the data (i.e., results contain very few negative eigenvector components). The eigenvector signs coming out of Matlab using its standard functions seem inside out (lots of negative components, including those of the first eigenvector), so to speak, for the matrix I’m currently considering.
I haven’t gotten to the time-series aspect yet. My over-arching goal is to feed my data into Matlab and then just let-her-rip with the calculations. I’m interested in doing this to avoid fiddling around with the many Excel cells, sheets, and formula-entry steps that would be needed (too many opportunities for human error).
If the Bro et al. approach leads to an eventual dead-end, I’m going to look into the ‘Eigenshuffle’ approach that John D’Errico takes, as documented at the Matlab Central File Exchange. It looks like it involves finding distances between the sequence of matrices.
These are just possible leads. I hope what I’ve written makes sense! If it does, could you please explain it to me, too? Ha ha.
Sarah,
Thanks for your explanation. I expect to come back to the issue of eigenvalues/eigenvectors later this year, at which time I will follow up on the approaches that you referenced.
My immediate priority is to release a new version of the websitethis week with a focus on reampling and some bug fixes. I also plan to release an online book on statistics to accompany this website, which I hope to make available this month.
Charles
Great site and software, Charles. How does eVECTORS handle the sign indeterminacy issue that is intrinsic to eigenvectors? Some call it the eigenvector sign-flip problem. In a purely mathematical sense, the phenomenon doesn’t matter at all. But if you’re doing data analysis on a ‘time series’ of covariance matrices, consistent eigenvector sign results are desirable.
Sarah,
Thank you for your comment. Thus far the eVECTORS function doesn’t do anything special about the sign. The signs are whatever are produced by the algorithm. What is your suggestion rearding how the sign ambiguity should be resolved?
Charles