Objective
When there are a large number of potential independent variables that can be used to model the dependent variable, the general approach is to use the fewest number of independent variables that can do a sufficiently good job of predicting the value of the dependent variable. This leads to the concept of stepwise regression, which was introduced in Testing Significance of Extra Variables. The reader is once again alerted to the limitations of this approach, as described in Testing Significance of Extra Variables.
Approach
on this webpage, we describe a different approach to stepwise regression based on the p-values of the regression coefficients. The algorithm we use can be described as follows where x1, …, xk are the independent variables and y is the dependent variable:
0. Establish a significance level. Whereas for most statistical tests a value of alpha = .05 is chosen, here it is more common to choose a higher value such as alpha = .15 or .20.
1a. Build the k linear regression models containing one of the k independent variables. Choose the independent variable whose regression coefficient has the smallest p-value in the t-test that determines whether that coefficient is significantly different from zero. Let’s call this variable z1 (i.e. z1 is one of the independent variables x1, …, xk) and the p-value for the z1 coefficient in the regression of y on z1 is p.
1b. If p ≥ α. Then stop and conclude there is no acceptable regression model. Otherwise, continue to step 2a.
2a. Assuming that we have now built a stepwise regression model with independent variables z1, z2, …, zm (after step 1b, m = 1), we look at each of the k–m regression models in which we add one of the remaining k-m independent variables to z1, z2, …, zm. As in step 2a, choose the independent variable whose regression coefficient has the smallest p-value. Let’s call this variable zm+1 and suppose the p-value for the zm+1 coefficient in the regression of y on z1, z2, …, zm, zm+1 is p.
2b. If p ≥ α. Then stop and conclude that the stepwise regression model contains the independent variables z1, z2, …, zm. Otherwise, continue on to step 2c.
2c. Now consider the regression model of y on z1, z2, …, zm+1 and eliminate any variable zi whose regression coefficient in this model is greater than or equal to α. This leaves us with at most m+1 independent variables. Now loop back to step 2a.
Note that this process will eventually stop. In order to make this process clearer, let’s look at an example.
Example
Example 1: Carry out stepwise regression on the data in range A5:E18 of Figure 1.
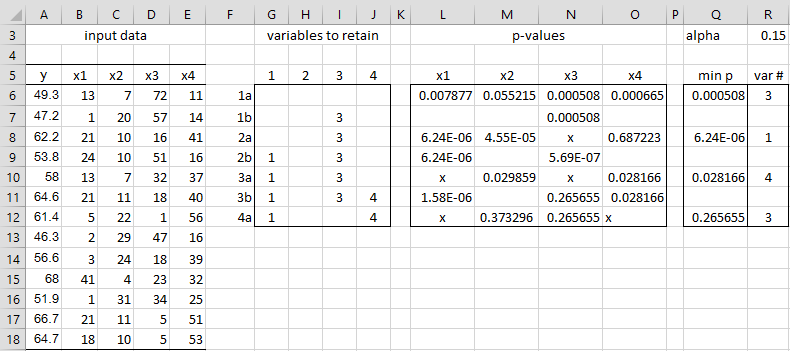
Figure 1 – Stepwise Regression
The steps in the stepwise regression process are shown on the right side of Figure 1. Columns G through J show the status of the four variables at each step in the process. An empty cell corresponds to the corresponding variable not being part of the regression model at that stage, while a non-blank value indicates that the variable is part of the model. We see that the model starts out with no variables (range G6:J6) and terminates with a model containing x1 and x4 (range G12:J12).
Columns L through O show the calculations of the p-values for each of the variables. The even-numbered rows show the p-values for potential variables to include in the model (corresponding to steps 1a and 2a in the above procedure). An “x” in one of these cells indicates that the corresponding variable is already in the model (at least at that stage) and so a p-value doesn’t need to be computed.
Steps
E.g. the value in cell L6 is the p-value of the x1 coefficient for the model containing just x1 as an independent variable. The value in cell L8 is the p-value of the x1 coefficient for the model containing x1 and x3 as independent variables (since x3 was already in the model at that stage). The values in range L8:O8 are computed using the array worksheet formula =RegRank($B$6:$E$18,$A$6:$A$18,G8:J8), which will be explained below.
For each even row in columns L through O, we determine the variable with the lowest p-value using formulas in columns Q and R. E.g. cell Q6 contains the formula =MIN(L6:O6) and R6 contains the formula =MATCH(Q6,L6:O6,0). Thus we see that variable x3 is the first variable that can be added to the model (provided its p-value is less than the alpha value of .15 (shown in cell R3). This we test in cell J7 using the formula =IF($R6=J$5,J$5,IF(J6=””,””,J6)).
The odd-numbered rows in columns L through O show the p-values that are used to determine the potential elimination of a variable from the model (corresponding to step 2b in the above procedure). These p-values are calculated using the array formula
=RegCoeffP($B$6:$E$18,$A$6:$A$18,G7:J7)
which we will describe below. A blank value in any of these rows just means that the corresponding variable was not already in the model and so can’t be eliminated.
Variable elimination
The determination of whether to eliminate a variable is done in columns G through J. For example, the test as to whether to eliminate the variable x4 from the model at the second step (when we have just added variable x1) is done in cell G10 using the formula =IF(L9>=$R$3,””,IF(G9=””,””,G9)). We see that x1 is not eliminated from the model. In the following step, we add variable x4 and so the model contains the variables x1, x3, x4). We now test x1 and x3 for elimination and find that x1 should not be eliminated (since p-value = 1.58E-06 < .15), while x3 should be eliminated (since p-value = .265655 ≥ .15).
In the final step of the stepwise regression process (starting with variables x1 and x4), we test variables x2 and x3 for inclusion and find that the p-values for both are larger than .15 (see cells M12 and N12).
Worksheet Functions
Real Statistics Functions: The Stepwise Regression procedure described above makes use of the following array functions. Here, Rx is an n × k array containing x data values, Ry is an n × 1 array containing y data values and Rv is a 1 × k array containing a non-blank symbol if the corresponding variable is in the regression model and an empty string otherwise. If cons = TRUE (default) then regression with a constant term is used; otherwise regression through the origin is employed.
RegRank(Rx, Ry, Rv, cons) – returns a 1 × k array containing the p-value of each x coefficient that can be added to the regression model defined by Rx, Ry, and Rv.
RegCoeffP(Rx, Ry, Rv, cons) – returns a 1 × k array containing the p-value of each x coefficient in the regression model defined by Rx, Ry, and Rv.
We can also determine the final variables in the stepwise regression process without going through all the steps described above by using the following array formula:
RegStepwise(Rx, Ry, alpha, cons) – returns a 1 × k array Rv where each non-blank element in Rv corresponds to an x variable that should be retained in the stepwise regression model. Actually, the output is a 1 × k+1 array where the last element is a positive integer equal to the number of steps performed in creating the stepwise regression model. alpha is the significance level (default .15).
Data Analysis Tool
Real Statistics Data Analysis Tool: We can use the Stepwise Regression option of the Linear Regression data analysis tool to carry out the stepwise regression process.
For example, for Example 1, we press Ctrl-m, select Regression from the main menu (or click on the Reg tab in the multipage interface), and then choose Multiple linear regression. On the dialog box that appears (as shown in Figure 2.
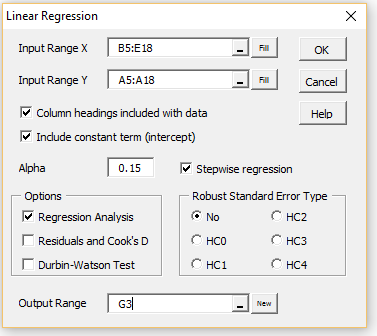
Figure 2 – Dialog box for stepwise regression
The output looks similar to that found in Figure 1, but in addition, the actual regression analysis is displayed, as shown in Figure 3.
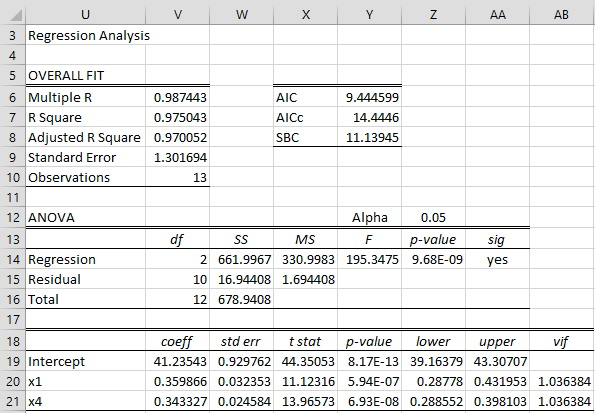
Figure 3 – Stepwise Regression output
Note that the SelectCols function is used to fill in some of the cells in the output shown in Figure 3. For example, the range U20:U21 contains the array formula =TRANSPOSE(SelectCols(B5:E5,H14:K14)) and range V19:W21 contains the array formula =RegCoeff(SelectCols(B6:E18,H14:K14),A6:A18). Here the range H14:K14 describes which independent variables are maintained in the stepwise regression model. This range is comparable to range H12:K12 of Figure 1 and contains the same values.
If the Include constant term (intercept) option is checked on the dialog box in Figure 2 then regression with a constant is used; otherwise, regression through the origin is employed.
Examples Workbook
Click here to download the Excel workbook with the examples described on this webpage.
Reference
Penn State University (2016) Stepwise regression
https://online.stat.psu.edu/stat501/Lesson10#stepwise-regression
Hello Charles, I was wondering whether – in principle – the stepwise procedure that you describe is also applicable for logistic regression?
The option doesn’t seem to be available under the ‘Logistic/Probit Regression’ dialogue box, but I suppose that the steps you describe in this article could be applied manually without the data analysis tool automation.
Regards, Akbar
Hello Akbar,
Yes, you could do something similar for logistic regression.
Charles
I think there may be two typos; if I am understanding correctly, then “Thus we see that variable x4 is the first variable”
Should refer to x3, not x4.
Also, “eliminate cell x4 from the model”, you probably meant to say “variable x4” rather than “cell x4”.
Thanks for providing this resource, it is an impressive work.
Hello Kevin,
Thank you very much for your comment. Yes, you are correct. I have just corrected the two typos.
I appreciate your help in improving the accuracy of the website.
Charles
Charles:
Why does the linear regression dialog box have a “Solver” check box right under the stepwise regression checkbox?
Hi Mark,
You can choose to perform the linear regression using Solver. This is not especially useful for most people.
Charles
OK, thanks.
Based on its position in the dialog box, I thought it might be related to stepwise regression, but that is not the case. So I was wondering what purpose it served.
Dear
How can we check if our linear multiple regression equation is not over-fitted after performing step wise regression? Is there anyway to check over-fitting and can you suggest reference as I need it to support my answer.
Thank you
Hello Estifanos,
In general, one way to determine the quality of predictions from a regression model (and so avoid overfitting) is to not use a portion of the available data to build the regression but use it to test the performance of the model. There is also a technique called cross-validation which enables you to use all your data to build the model. See
https://real-statistics.com/multiple-regression/cross-validation/
Charles
Dear Charles
Thank you.
I have one additional question. If the cross validation does not give me a good result, how can I make the multiple regression not to be over fitted? Is there any way to improve the over fitted regression equation?
Secondly, how can I apply non-linear multiple regression on excel (other than the one that you explained using exponential function, the example that you provided uses only one independent variable). I.e I want to know how to use solver for multiple non-linear regression? In addition, I would like to know how to choose a best non-linear equation for performing multiple regression on my data?
Thank you once again.
Hello Estifanos,
1. You might not be able to avoid over-fitting with a multiple linear regression model when CV doesn’t yield a good result.
2. You need to decide on a suitable non-linear model. The approach using Solver with more than one independent variable is the same as that using only one independent variable. E.g. you can use Solver for a logistic regression model with multiple independent variables. See
Logistic Regression using SolverLogistic Regression using Solver
3. The situation is more complicated if you use Newton’s method instead of Solver
4. You first need to decide what you mean by the best non-linear regression model. This can be defined as the model that has the lowest SSE (sum of squared errors) or you might choose to use a different criterion (e.g. the lowest sum of absolute errors). There is an infinite number of such non-linear models and so you also need to decide which models to consider.
Charles
Charles,
I’d like to report that the array function of “=UnStdRegCoeff ” does not work at this moment. I’ve tried multiple times, but the function returns with the undefined value notation for all regression coefficients. Can you check whether this function works properly? I will try to test again later days to ensure this is not an isolated case.
Thanks,
-Sun
Dear Charles,
I conducted a stepwise regression by using Real Statistics Resources Pack on Example 1 of the Collinearity webpage .
There are 8 independent variables, namely, Infant Mortality, White, Crime, Doctor, Traffic Death, University, Unemployed , Income.
Before the Stepwise Regression, I calculated the Tolerance and VIF of the 8 variables.
————————————————————————————————
1 2 3 4 5 6 7 8
variable Infant Mort White Crime Doctors Traf Deaths University Unemployed Income
Tolerance 0.388180115 0.480924192 0.482798572 0.261702267 0.104333643 0.102547092 0.518803875 0.224570896
VIF 2.576123714 2.079329793 2.07125716 3.821136181 9.584636102 9.751617297 1.927510662 4.452936762
—————————————————————————————————–
The above figures showed that only Traffic Death (with Tolerance=0.1043) and University (with Tolerance = 0.1025) deserved attention and might be eliminated due to collinearity.
I then conducted two stepwise regressions, one with Alpha = 0.05, and another with Alpha = 0.15. The former regression keeps only the “income” variable. The latter keeps only “Unemployed” and “Income”.
The Tolerance and VIF figures only suggested elimination of “Traffic Death” and “University”.
The Stepwise Regressions eliminated also “White”, Infant Mortality”, “Crime”, “Doctor”.
Why were these variables also eliminated by stepwise regression?
Dear Charles
Can Real Statistics Resources Pack support building a Generalized Linear Model?
Dennis
Dennis,
It supports some parts of the GLM. E.g. when it addresses an unbalanced Two Factor ANOVA using regression, it is using a GLM.
Charles
Dear Charles,
Thanks.
Will Real Statistics Resources Pack develop a function to build GLM?